1. 引言:为什么我们要聊”上下文缓存”?
在使用 Claude Code 或进行长对话开发时,你可能发现费用增长得远超预期。这是因为 Claude Code 与 LLM 的交互并不是简单的”你问我答”。
1.1 Claude Code 的后台”潜规则”
Claude Code 作为一个 Agent,它在后台与 LLM 交互时会携带巨大的工程负担(Harness Engineering):
- 庞大的系统提示词:包含了复杂的角色设定、工具使用说明。
- 动态注入的 Reminders:如 TODO 列表、文件编辑约束等。
- 完整的内容上下文:代码库片段、历史对话等。
这些”后台内容”往往占据了请求 Token 的 90% 以上。在无状态的 API 设计下,每一轮对话你都在为这些重复的”后台内容”买单。如果不使用缓存,费用会随着对话轮数呈线性甚至指数级上升。
具体解释:
- 上下文缓存:指把经常重复使用的”长文本”(如几十页的系统指令、背景资料)预先存到缓存里。下次请求时直接调用,无需重复上传,能大幅降低延迟和费用。
- TTL:指设定这段缓存的自动过期时间(比如5-10分钟)。一旦超出设定时间,缓存就会被清理,下次请求会重新计算。
用一个”图书馆”的比喻帮你理解:
- 上下文缓存:你第一次从书库找一本书(消耗算力),然后把它放在自己座位上。
- 后续查询:所有类似问题都直接从座位上翻书,秒回且便宜。
- TTL:图书馆规定座位保留1小时(TTL=3600秒)。时间一到,座位清空,书归还书库。这是为了确保数据实时性,并防止缓存无限占用资源。
2. 旁观者视角:使用 claude-tap 观察交互过程
在深入技术原理之前,我们先通过工具看看 Claude Code 到底在后台跟 LLM 说了什么。
claude-tap 是一个专门设计用来拦截、查看并分析 AI 命令行工具(如 Claude Code 和 Codex CLI)底层 API 流量的抓包与分析工具。当运行 claude-tap 时,它会在本地启动一个 HTTP 服务。它通过环境变量(如 ANTHROPIC_BASE_URL 或 OPENAI_BASE_URL)将后端的 AI 客户端(如 Claude Code)原本要发往官方服务器的流量,强行”劫持”/重定向到本地的这个代理端口。随后,代理服务器再将请求转发给真正的上游官方 API(如 api.anthropic.com)。在这个过程中,claude-tap 可以无缝地捕获所有经过的 Request 和 Response,并记录流式数据(SSE)。
claude-tap github地址:https://github.com/liaohch3/claude-tap
2.1 Trace!
直接看文档往往是枯燥的。通过 claude-tap,你可以实时抓取并解剖真实的 API 报文,看到那些被 CLI 隐藏起来的秘密。
- 运行claude-tap命令:
claude-tap --tap-live --tap-target https://ai.uniontech.com/api/v1 --tap-no-launch --tap-host 127.0.0.1 --tap-port 8080
- 启动claude:
- 将
~/.claude/settings.json中ANTHROPIC_BASE_URL改为http://127.0.0.1:8080 - 执行
claude
- 将
2.2 你会发现什么?
- 隐藏的 System Reminders:你会发现 Claude Code 经常在你的 User Message 前面加上一堆
<system-reminder>。 - 真实的
cache_control:你会看到报文中某些 Block 的末尾带有{"type": "ephemeral"}标记。 - 缓存命中情况:在响应的
usage字段中,你会看到cache_read_input_tokens到底省了多少钱。
3. 技术原理:KV Cache 与 TTL
3.1 Transformer 的”原罪”:$O(n^2)$ 复杂度
在 Transformer 架构中,核心的 Self-Attention(自注意力) 机制要求每一个 Token 都要与序列中其他所有 Token 计算相关性:
- 原理:如果你有 $n$ 个 Token,第 1 个要跟 $n$ 个比,第 2 个也要跟 $n$ 个比……最终需要进行 $n \times n$ 次运算。
- 计算成本:随着序列长度 $n$ 的增加,计算量按平方级增长。这意味着 2 倍的长度需要 4 倍的计算资源。
- KV Cache:为了加速生成过程,模型会将之前计算好的 Key (K) 和 Value (V) 向量存起来,避免重复计算旧 Token 的向量。
3.2 API 的”断片”:无状态设计
虽然模型内部有 KV Cache,但标准 API 请求结束后会立即清空。下一轮请求,哪怕只多了一个字,也要重新计算之前成千上万个 Token 的 KV 值。
3.3 Prompt Caching:跨请求的”持久记忆”
通过在请求中加入 cache_control (Anthropic API,以下的API相关也指Anthropic API),LLM 厂商会将这部分计算好的 KV Cache 存储在服务端,并分配一个 TTL(Time-to-Live,生存时间)。
- 不同模型的 TTL 策略:
- Qwen (百炼):TTL 默认为 5 分钟。每次命中后都会重置这 5 分钟倒计时。
- Anthropic (Claude):通常提供 5 分钟 或 1 小时 两种生存周期(取决于具体的缓存类型和配置)。
- DeepSeek:不适用上述 TTL 机制。它采用的是上下文磁盘缓存,默认开启的,这种方式更加持久,时间一般为几个小时到几天,只要内容命中其缓存池即可。所以我们在claudecode中使用deepseek时,cache_creation_input_tokens总是为0,它不会收取缓存创建的费用。
- GLM: 自动缓存识别(隐式缓存),智能识别重复的上下文内容,无需手动配置。
发起 API 请求
↓
是否存在缓存前缀?
├── 是 → 从缓存服务读取 KV Cache
│ 只计算/推理新增 Token
│
└── 否 → 模型重新计算全量 KV Cache
写入持久化缓存并设置 TTL
↓
返回响应
刷新 TTL 倒计时
重要提示 缓存的作用域(隔离机制): 缓存并不是全局共享的,通常遵循严格的隔离逻辑(以 Qwen/Claude 为例):
- 账号隔离:只有同一个账号下的请求才能命中。
- 模型隔离:缓存绑定到特定模型,例如 Qwen3.6 的缓存无法被 Qwen3.5 使用。
- 前缀一致性:必须是 100% 相同的前缀才能触发命中。
4. Claude API 的缓存启用方式
在调用 API 时,claude code有两种方式启用 Prompt Caching:
4.1 自动缓存
这是最简便的方式,适合大多数对话场景。只需在请求顶层添加一行:
"cache_control": {"type": "ephemeral"}
示例:
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
cache_control={"type": "ephemeral"},
system="You are a helpful assistant that remembers our conversation.",
messages=[
{"role": "user", "content": "My name is Alex. I work on machine learning."},
{
"role": "assistant",
"content": "Nice to meet you, Alex! How can I help with your ML work today?",
},
{"role": "user", "content": "What did I say I work on?"},
],
)
print(response.usage.model_dump_json())
在多轮对话中,系统会自动将缓存断点标记在最后一个可缓存的 Block(通常是最后一条 User 消息)。
4.2 显式缓存断点
如果你需要更精细的控制,可以在特定的内容块中手动放置 cache_control。
- 核心特性:
- 多重缓存槽:一个请求中最多可以设置 4 个 显式断点。
- 累积哈希:每个断点的缓存内容是从开头到该断点的所有内容的哈希值。这意味着只要前面的内容有变,后续所有断点的缓存都会失效。
- 缓存层级结构:Tools → System → Messages ,每个层级的变化都会使该层级及后续所有层级失效(Tools不支持添加
cache_control, Tools会作为system 消息缓存的一部分)。
- 适用场景:
- 长 System Prompt:如果你的系统提示词长达数万 Token,可以单独给它打一个断点。
- 固定参考资料:在
messages中间插入大型文档,并在文档末尾设置断点。
- 配置示例:
在
messages数组或system字段中,将content改为数组形式,并在目标 Block 中注入标记:{ "role": "system", "content": [ { "type": "text", "text": "这里是数万 Token 的静态知识库或复杂的系统指令...", "cache_control": { "type": "ephemeral" } } ] }
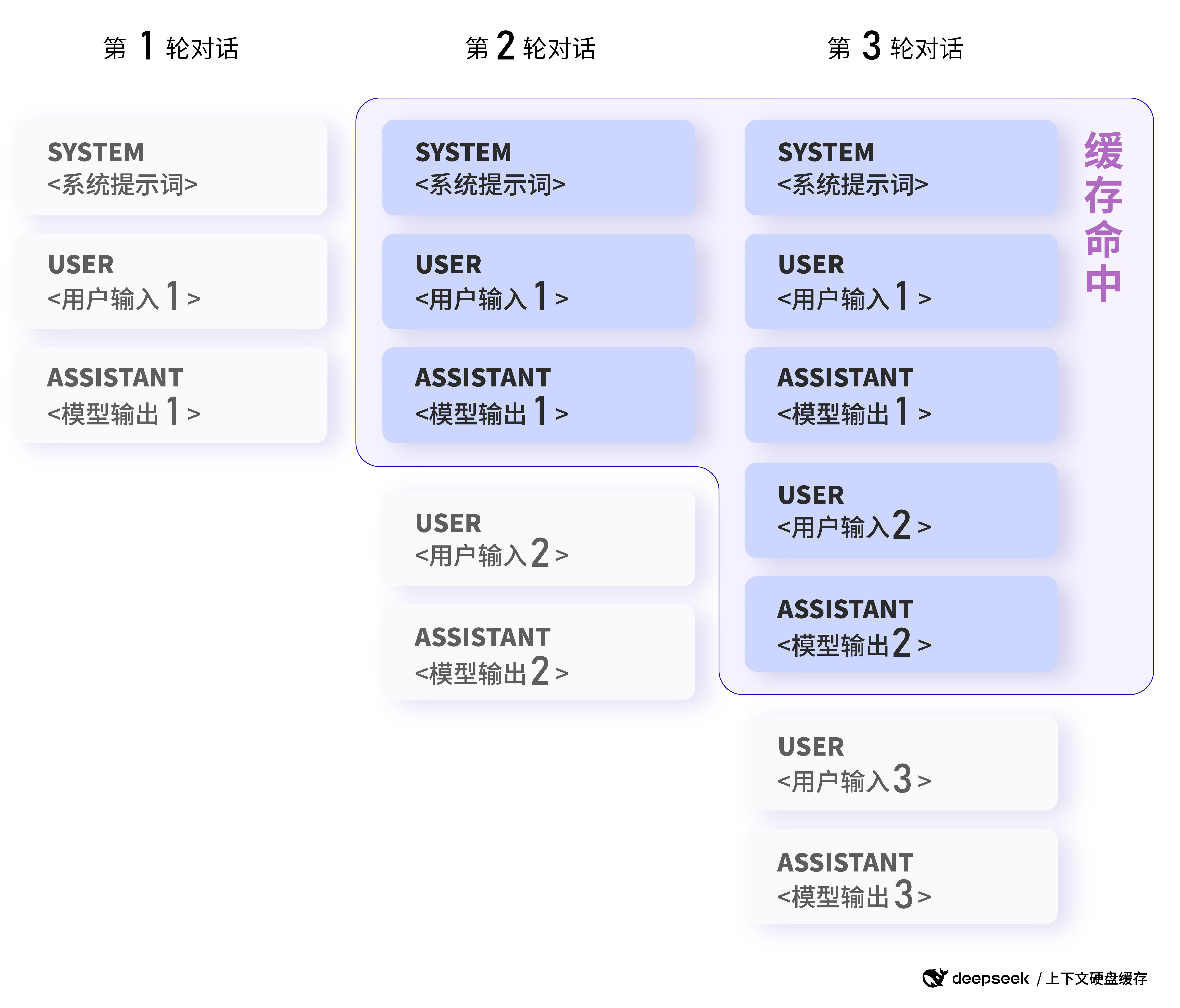
4.3 机制直观演示:多轮对话中的缓存流转
无论是自动还是显式缓存,Claude Code 在多轮对话中都帮我们默认加了 cache_control, 流转规律如下:
| 回合 | 发送内容 | 缓存行为 |
|---|---|---|
| R1 | System + User1 | 写入 System + User1 到缓存 |
| R2 | System + User1 + Asst1 + User2 | 读取 S+U1,写入 A1+U2 |
| R3 | S + U1 + A1 + U2 + Asst2 + User3 | 读取 S+U1+A1+U2,写入 A2+U3 |
通俗易懂地理解缓存差异:
- A. 缓存命中:
[ 已缓存内容(tools + system prompt + conversation history) ]+{ 新对话 }→ 仅需计算/支付{ 新对话 }的费用,旧内容直接复用。 - B. 缓存失效:
[ 过期或无效内容(tools + system prompt + conversation history)]+{ 新对话 }→ 全量 内容都需要重新计算并重新支付”写入费”。
续杯机制:每一轮请求成功后,新的内容都会被写入缓存并重新计时 TTL。只要两次请求间隔小于 TTL,你就可以实现”无限续杯”,只为新增内容支付写入费。
4.4 关键约束:块匹配与回溯
- 100% 匹配:请求中的
tools[]、system[]、messages.content[]缓存的内容块必须一个字符不差。 - 20 Block 回溯:系统最多往前查找 20 个内容块来寻找曾经写入过的缓存。
- 最小阈值:Claude Sonnet/ Qwen3 通常需要 >1024 Tokens 才开启缓存。
5. 实验数据对比:省了多少钱?
我们通过调用 API 后,从 LLM 返回的 usage 字段中解析相关参数,精准获取了每一轮对话的缓存状态。
5.1 监控缓存表现
你可以通过 API 响应中 usage 对象(如果是流式输出,则在 message_start 事件中)的以下字段来监控缓存性能:
cache_creation_input_tokens:创建新缓存条目时写入缓存的 Token 数量。cache_read_input_tokens:本次请求中从缓存中读取(命中)的 Token 数量。input_tokens:既不属于缓存读取也不属于创建缓存的普通输入 Token 数量(即最后一个缓存断点之后的内容)。
根据 ttl_cache_demo.py 的实测数据,我们对比了约 6000+ Tokens 上下文在多轮交互中的费用变化:
5.2 价格乘数 (以 Anthropic/Qwen 为例)
Qwen 和 Anthropic 的缓存定价乘数一致:
- Cache Write (写入): 基础价格 × 1.25
- Cache Read (命中): 基础价格 × 0.1 (节省 90%!)
5.3 实测成本对比表 (以 Qwen 3.5 实验数据为例)
3 轮对话实测数据
| 场景 | 输入 Tokens (总计) | 输入成本 (估算) | 备注 |
|---|---|---|---|
| 无缓存场景 | 18,584 | ¥0.003717 | 每次请求都全量重新计算 |
| Prompt Caching | 18,584 | ¥0.001802 | 输入成本节省 ~51.5% |
计算公式
以 Qwen3.5 价格为例:
- 输入基础价格:¥0.2/M tokens
- Cache Write:基础价格 × 1.25 = ¥0.25/M tokens
- Cache Read:基础价格 × 0.1 = ¥0.02/M tokens
- 输出价格:¥2.0/M tokens
单轮请求的输入成本计算: \(\text{成本} = \frac{\text{cache\_read} \times 0.02 + \text{cache\_write} \times 0.25 + \text{input\_tokens} \times 0.2}{1,000,000} \text{(元)}\)
无缓存场景(TTL 过期或首次请求): \(\text{成本} = \frac{\text{总输入tokens} \times 0.25}{1,000,000} \text{(全额写入费)}\)
缓存命中场景: \(\text{成本} = \frac{\text{命中tokens} \times 0.02 + \text{新增tokens} \times 0.25}{1,000,000}\)
多轮对话成本推演
假设每轮对话结构:
- 固定部分(System + Tools):10000 tokens
- 历史对话增量:每轮 +1000 tokens(含 assistant 回复)
- 新增用户输入:200 tokens
| 轮次 | 无缓存输入成本 (¥0.2/M) | 有缓存输入成本 (¥0.02 命中 + ¥0.25 写入) | 单轮输入节省 | 累计输入节省 |
|---|---|---|---|---|
| R1 | 10200×0.2 = ¥0.00204 | 10200×0.25 = ¥0.00255 | -25% | -25% |
| R2 | 11400×0.2 = ¥0.00228 | 10200×0.02+1200×0.25 = ¥0.00050 | 78.1% | 26.5% |
| R3 | 12600×0.2 = ¥0.00252 | 11400×0.02+1200×0.25 = ¥0.00053 | 79.0% | 44.9% |
| R5 | 15000×0.2 = ¥0.00300 | 13800×0.02+1200×0.25 = ¥0.00058 | 80.7% | 59.9% |
| R10 | 19800×0.2 = ¥0.00396 | 18600×0.02+1200×0.25 = ¥0.00067 | 83.1% | 72.6% |
| R20 | 29400×0.2 = ¥0.00588 | 28200×0.02+1200×0.25 = ¥0.00092 | 84.4% | 81.2% |
| R30 | 39000×0.2 = ¥0.00780 | 37800×0.02+1200×0.25 = ¥0.00118 | 84.9% | 84.6% |
关键发现:
- R1 反而更贵:首轮需要支付 1.25x 写入费,比无缓存贵 25%
- R2 瞬间回本:缓存命中后成本骤降 78%,两轮累计已实现正向收益
- 边际收益递减:随着轮次增加,单轮节省比例趋近 90% 极限
- 累计效应显著:30 轮对话整体节省 84.6% 输入成本
结论
设每轮新增 $\Delta$ tokens,第 $n$ 轮总输入 tokens 为 $T_n$:
\[\begin{aligned} \lim_{n \to \infty} \text{节省比例} &= \lim_{n \to \infty} \frac{\text{无缓存成本} - \text{有缓存成本}}{\text{无缓存成本}} \\[8pt] &= \lim_{n \to \infty} \frac{T_n \times 1 - \left( T_n \times 0.1 + \Delta \times 1.25 \right)}{T_n \times 1} \\[8pt] &= 1 - 0.1 - \lim_{n \to \infty} \frac{1.25 \Delta}{T_n} \\[8pt] &= 90\% \quad \left( \text{因为 } \frac{\Delta}{T_n} \to 0 \right) \end{aligned}\]核心逻辑:轮次越多,每轮新增 tokens 占比越小,cache_write (1.25x) 的成本可忽略,几乎所有输入都按 cache_read (0.1x) 计价。
\[\text{有缓存成本} = \underbrace{T_n \times 0.1}_{\text{cache read部分成本}} + \underbrace{\Delta \times 1.25}_{\text{cache creation部分成本}}\]随着请求量 $n$ 的增大,总请求Tokens输入的量 $T_n$ 线性增长($T_n \to \infty$)。
\[\lim_{n \to \infty} \frac{1.25 \Delta}{T_n} = 0\]这意味着每轮会话新增 $\Delta$ tokens 在当前会话历史上下文tokens总和 $T_n$ 面前变得微不足道。
轮次越多,缓存命中占比越高,成本越接近理论极限 90%。在长对话或 Agent 循环场景中,Prompt Caching 是降本增效的利器。
成本节省潜力: 以上实测数据仅基于 3 轮对话。在 20-30 轮的长对话或 Agent 循环中,随着 命中 (0.1x) 占比不断提高,输入侧的成本节省通常能达到 80% - 90%,同时能显著降低首字延迟(TTFT)。
6. 实战建议:如何更省钱?
- 不要中途切换模型:缓存是模型隔离的。如果你从
qwen3.5切换到qwen3.6,哪怕上下文完全一样,之前的缓存也无法被新模型读取,会导致昂贵的重新写入。 - 离场前压缩:若需长时间离开(超过 5 分钟),可以使用 Claude Code 的
/compact或相关命令触发总结机制,将繁琐的对话历史压缩为memory,下次回来时虽然 TTL 已过,但起点的 Token 总数会显著降低。 - 定期减负:养成使用
/clear或/rewind的习惯。不要让上下文无限制增长,及时清理掉不再需要的中间过程。 - 集中饱和式工作:利用 TTL 的 5min 规则。在处理复杂任务时,尽量在 5 分钟内连续提问,保障缓存始终处于存活状态,最大化利用 0.1x 的命中价格。
- 监控命中率:通过检查 API 返回
usage字段的习惯,或者通过/usage或者statusline实时观察cache_read_input_tokens。只有让自己清楚看到钱花在哪里了,才能总结出自己的省钱方法。 - 不要动态调整 Skills:添加或删除 Skill 会改变系统提示词(Skills 定义会被注入到 System Prompt 中),导致前缀发生变化,从而使 User Prompt 缓存失效。如需调整 Skills,建议在新会话中进行。
更多关于缓存失效的官方说明,请参考:Anthropic Prompt Caching Documentation